
یادگیری ماشین با نظارت | Supervised Machine Learning نوعی یادگیری است که در آن ماشین یا مدل با استفاده از داده های آموزشی (دارای برچسب صحیح) آموزش داده می شود تا بتواند برای داده های تستی یا جدید، فرایند تشخیص برچسب (تشخیص خروجی یا پیش بینی خروجی) را انجام دهند. منظور از داده های دارای برچسب این است که برخی از داده های ورودی قبلاً با خروجی صحیح برچسب گذاری شده اند.
داده های آموزشی (دارای برچسب صحیح) در یادگیری ماشین با نظارت | Supervised Machine Learning برای آموزش یک مدل یا ماشین استفاده می شود تا بعدها آن مدل بتواند با توجه به آموزش فرا گرفته شده در امتحانات نمره خوبی کسب کند. منظور از امتحانات، همان پیش بینی برچسب صحیح برای داده های ورودی جدید می باشد. شما می تواند این پاراگراف را از طریق مثال یک دانش آموز و معلم بهتر درک کنید. به عنوان مثال در مدرسه، معلم سوالات و پاسخ های صحیح را به دانش آموز آموزش می دهد و در پایان ترم از دانش اموز امتحان می گیرد، اگر دانش آموز بتواند برای سوالات، پاسخ های درستی بنویسید نمره خوبی کسب می کند در غیر این صورت ممکن از رفوزه شود.
در دوره آموزشی جامع علم داده مدرس کاظم تقندیکی تمام A-Z علم داده (یادگیری ماشین، داده کاوی) را به شکل کاملاً عملی و با زبانی ساده به شما آموزش می دهد
هدف یک الگوریتم یادگیری با نظارت، یافتن یک تابع نگاشت برای ترسیم متغیر ورودی (x) با متغیر خروجی (y) است یا نگاشت یک سوال به یک پاسخ صحیح می باشد.
در دنیای واقعی، از یادگیری با نظارت می توان برای ارزیابی ریسک، طبقه بندی تصویر، تشخیص تقلب، فیلتر هرزنامه و غیره نیز استفاده کرد.
یادگیری با نظارت | Supervised Machine Learning چگونه کار می کند
در یادگیری نظارت شده | Supervised Machine Learning، مدلها با استفاده از مجموعه دادههای برچسبگذاری شده آموزش داده میشوند، پس از تکمیل فرآیند آموزش، مدل بر اساس داده های آزمون دارای برچسب واقعی (زیرمجموعه ای از مجموعه داده) آزمایش می شود تا برای آن ها خروجی صحیح را پیش بینی کند. اگر خروجی بدست امده شده مانند خروجی واقعی داده های آزمون باشد می توانیم بگیم مدل ما از دقت خوبی برخوردار است و می تواند در کسب و کار به منظور افزایش سود دهی از آن استفاده کرد در غیر اینصورت باید به فکر چاره در فرآیند کار بود.
فرض کنید مجموعه داده ای از انواع مختلف اشکال داریم که شامل مربع، مستطیل، مثلث و چند ضلعی است. اکنون اولین قدم این است که باید مدل را برای هر شکل آموزش دهیم.
- اگر شکل داده شده چهار ضلع داشته باشد و همه اضلاع آن برابر باشند، آن را به عنوان مربع علامت گذاری می کنیم .
- اگر شکل داده شده دارای سه ضلع باشد، به عنوان یک مثلث علامت گذاری می شود .
- اگر شکل داده شده شش ضلع مساوی داشته باشد، به عنوان شش ضلعی علامت گذاری می شود .
حالا بعد از گام آموزش، مدل خود را با استفاده از مجموعه تست ( آزمایش )، تست (ارزیابی) می کنیم تا ببینیم برای شکل های تستی به درستی فرایند تشخیص نوع شکل را با توجه به تعداد اضلاع آن، انجام می دهد یا خیر.
در دوره آموزشی جامع علم داده مدرس کاظم تقندیکی تمام A-Z علم داده (یادگیری ماشین، داده کاوی) را به شکل کاملاً عملی و با زبانی ساده به شما آموزش می دهد
مراحل مربوط به یادگیری با نظارت:
- ابتدا یک مجموعه داده یا دیتاست انتخاب می کنیم.
- سپس مجموعه داده را به مجموعه داده آموزشی (75 درصد داده ها) و مجموعه داده آزمایشی (25 درصد داده ها) تقسیم کنید.
- ویژگی های ورودی مجموعه داده آموزشی را تعیین کنید، که باید دانش کافی داشته باشد تا مدل بتواند خروجی را از طریق آن ها به طور دقیق پیش بینی کند.
- یک الگوریتم یادگیری ماشین از نوع با نظارت (مانند ماشین بردار پشتیبان، درخت تصمیم) را با توجه به ساختار داده های آموزشی و آزمایشی انتخاب می کنیم
- الگوریتم را روی مجموعه داده آموزشی اجرا کنید تا مدل آموزش دیده ساخته شود.
- با ارائه مجموعه تست، دقت مدل ساخته شده از مرجله قبل را ارزیابی می کنیم.
در دوره آموزشی جامع علم داده مدرس کاظم تقندیکی تمام A-Z علم داده (یادگیری ماشین، داده کاوی) را به شکل کاملاً عملی و با زبانی ساده به شما آموزش می دهد
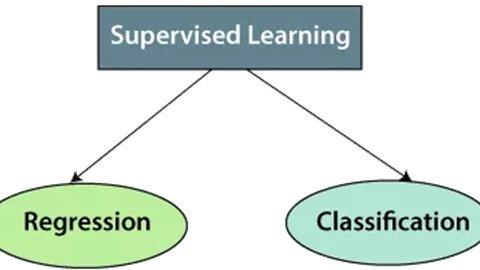
انواع الگوریتم های یادگیری ماشینی تحت نظارت
رگرسیون
اگر رابطه ای (مثل رابطه افزایشی یا کاهشی) بین متغیر ورودی (ویژگی ها) و متغیر خروجی (برچسب) وجود داشته باشد از الگوریتم های رگرسیون استفاده می شود. از این نوع الگوریتم ها برای پیشبینی متغیرهای پیوسته، مانند پیشبینی آبوهوا، روند بازار، و غیره استفاده میشود. در ادامه انواع الگوریتم های رگرسیون ذکر شده است.
- رگرسیون خطی
- درختان رگرسیون
- رگرسیون غیر خطی
- رگرسیون خطی بیزی
- رگرسیون چند جمله ای
دسته بندی
از الگوریتمهای دسته بندی زمانی استفاده میشوند که متغیر خروجی از نوع طبقه بندی ( Categorical ) باشد یا بتوان آن را به این نوع تبدیل کرد، به این معنی که متغیر خروجی از نوع دو کلاسه مانند بله-نه، مذکر-مونث، درست-کاذب و غیره وجود باشد. در ادامه انواع الگوریتم های دسته بندی لیست شده اند.
- جنگل تصادفی | Random Forest
- درخت تصمیم
- رگرسیون لجستیک
- ماشین بردار پشتیبان | SVM
مزایای یادگیری با نظارت
- با استفاده از یادگیری با نظارت، مدل می تواند خروجی را بر اساس تجربیات قبلی (آموزش) پیش بینی کند.
- در یادگیری نظارت شده، میتوانیم ایده دقیقی درباره کلاسهای اشیاء داشته باشیم.
- مدل به دست آمده در یادگیری نظارت شده به ما کمک می کند تا مشکلات مختلف دنیای واقعی مانند کشف تقلب، فیلتر هرزنامه و غیره را حل کنیم.
معایب یادگیری با نظارت
- مدل های یادگیری با نظارت برای انجام وظایف پیچیده مناسب نیستند.
- اگر داده های آزمون با مجموعه داده آموزشی متفاوت باشد، یادگیری تحت نظارت نمی تواند خروجی صحیح را پیش بینی کند.
- گام آموزش در الگوریتم های یادگیری با نظارت به زمان محاسباتی زیادی نیاز دارد.
- در یادگیری نظارت شده، ما به دانش کافی در مورد طبقات داده ها نیاز داریم..

 آموزش راه اندازی NAT Extendable در Cisco IOS
آموزش راه اندازی NAT Extendable در Cisco IOS دوره آموزش نتورک پلاس چیست؟ 20 نکته دوره نتورک پلاس که نمیدانید
دوره آموزش نتورک پلاس چیست؟ 20 نکته دوره نتورک پلاس که نمیدانید RedHat چیست؟ معرفی لینوکس توزیع RHEL به زبان بسیار ساده
RedHat چیست؟ معرفی لینوکس توزیع RHEL به زبان بسیار ساده سی شارپ چیست؟ معرفی کامل C# به همراه مزایا ، معایب و کاربردها
سی شارپ چیست؟ معرفی کامل C# به همراه مزایا ، معایب و کاربردها شبکه چیست؟ تعریف انواع شبکه های کامپیوتری به زبان ساده
شبکه چیست؟ تعریف انواع شبکه های کامپیوتری به زبان ساده معرفی دوره های آموزشی هک وب سایت یا تست نفوذ وب + نقشه راه
معرفی دوره های آموزشی هک وب سایت یا تست نفوذ وب + نقشه راه 21 سوال مهم برای یادگیری و آموزش لینوکس قبل از شروع دوره لینوکس
21 سوال مهم برای یادگیری و آموزش لینوکس قبل از شروع دوره لینوکس ریسک افزار چیست؟ آشنایی با مفهوم Rsikware به زبان ساده
ریسک افزار چیست؟ آشنایی با مفهوم Rsikware به زبان ساده برنامه نویسی را از کجا شروع کنیم؟ مسیر یادگیری برنامه نویسی
برنامه نویسی را از کجا شروع کنیم؟ مسیر یادگیری برنامه نویسی